Fixing Hung Nginx Workers
While cleaning up some tech debt, a curious issue cropped up. Nginx was running in an alpine container as a front end load balancer. It had a dynamic config that got periodically updated by a sidecar, and had filebeat shipping logs out to a central collector but otherwise was just a very simple Nginx config.
Every now and then the container would crash, it would automatically recover fast enough no alarms were lost and the clients would just resend their requests. No data was lost, everything failed gracefully, but it's still a pretty crazy thing to leave happening.
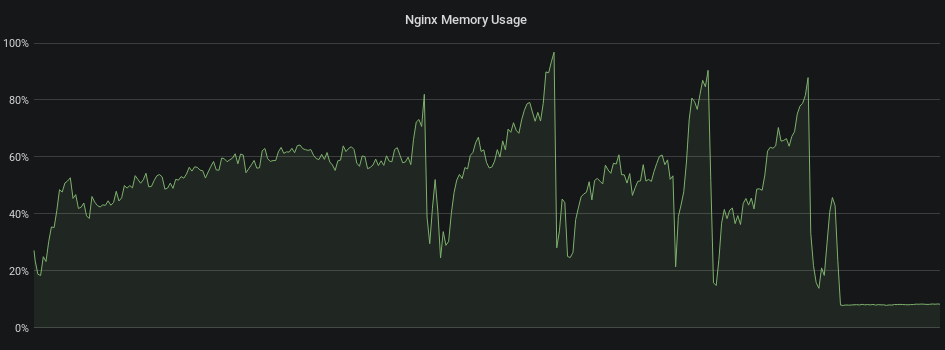
There was nothing in the log besides some client errors and configuration reloading notifications. The external metrics showed the container throwing some kind of memory party before finally burning out and crashing. It was a pretty steady trend upwards indicative of some kind of a memory leak. The graph below illustrates this. Each of those drops is either the container crashing or me manually restarting it to test behavior. Can you figure out when I fixed the issue?
To figure out what was going on I had to get an invitation that container's party.
I don't think there is great tooling for inspecting individual processes inside of containers. As much as we'd like to think of containers as isolated applications, its not uncommon for them to run a minimal init container, or be composed of separate different processes themselves that handle different things (Nginx has a master process and spawns off many worker processes). We still need the data on those processes.
The common solution to getting this data seems to be to "just exec into the container". In general exec should be restricted. If you find yourself running exec in a container, you're missing tooling or metrics that should avoid that (which is the case here).
Denying exec is probably a longer discussion but the short of it is: If you can exec into the container, you can extract its secrets, configuration, and access any services that it's allowed to (likely escalating your personal privileges within the cluster). This is without considering the ramifications of exec'ing into a privileged container.
In any event, not all container clusters solution allow external execution (looking at you AWS ECS, its the one good thing I have to say about you).
I chose to modify the container to log the data I needed instead. I setup a wrapper that started and backgrounded the following script:
| |
I'm slightly abusing awk to generate JSON I can parse later, but it works and it doesn't need to be fancy.
Each message has a prefix of "memstat:" so I can easily filter and extract that data from the live log stream. After a couple of hours (the time it generally took for the party to get going) the issue was pretty obvious. Inside the container there was a growing number of processes with the name "nginx: worker process is shutting down". Some Googling turned up a post in the Nginx mailing list from a while ago.
The responses claimed that it was the result of a third party module, but this is stock Nginx (version 1.15.8 at the time) which was at least three years older than the post. It did indicate a clue though: config reloading.
I don't know why Nginx believed connections were still open, we have request and connect timeouts both in this config and upstream. Some of these processes were sticking around for hours (I never actually saw one exit after getting into this hung state). Every config reload was dropping a zombie worker or two into the container, permanently consuming ~30Mb of RAM. When it hit the configured threshold, the party gets stopped.
An option was added in the Nginx core module to handle situations where the worker wouldn't close, but this definitely seems like a bug of some kind. There is a newer version of Nginx (1.17.5 at the time of the writing) that could very well have fixed this issue.
Adding "worker_shutdown_timeout 60s;" to the main Nginx config solved the issue (60 seconds matches our request and connect timeouts so nothing valid should last longer than that). Sure enough Nginx went back to stable, and predictably low memory usage.
linux nginx operations diagnostics
ac3c177e @ 2024-07-15